
Website Crawling, often overlooked but vitally important, is the cornerstone of successful search engine optimization (SEO). It refers to how effectively search engines can explore and index your website. In this comprehensive guide, we’ll delve into various techniques and strategies for optimizing your website’s crawlability, guaranteeing that it tops the search engine results and provides an excellent user experience. We’ll explore each point in detail.
What is Website Crawling?
Website crawling is a fundamental process in the world of search engines and online indexing. It’s the mechanism by which search engine bots systematically navigate and scan websites to gather information about their content. Think of it as a digital explorer charting a map of the internet.
During website crawling, specialized programs, often referred to as web crawlers or spiders, follow links from one webpage to another. They start from a seed URL, which can be any webpage on the internet, and then move from link to link, parsing the HTML code of each page they encounter. These crawlers index the content, keywords, images, and other elements of web pages, storing this data in a massive database.
The primary purpose of website crawling is to build a searchable index of the web’s content. Famous search engines like Google, Bing, Yandex, Baidu, etc., use this index to respond to user queries with relevant search results. The frequency and depth of website crawling can vary, with popular and frequently updated websites getting crawled more often to ensure search results reflect the most current information.
In essence, website crawling is the foundation of how search engines discover, analyze, and serve web content to users, making it a critical aspect of online visibility and accessibility.
Ways to Enhance Website Crawling
1. Locking the Index Page with a Meta Tag
Sometimes, it’s necessary to prevent search engines from indexing your homepage, such as when you’re working on a new site or need to hide certain content. You can achieve this by adding a “noindex” meta tag to your index page’s HTML. This tag instructs search engines not to include the page in their index. However, use this technique sparingly, as it’s generally more suitable for specific scenarios rather than a long-term strategy.
Implementation:
To lock the index page with a meta tag, add the following code to the <head> section of your HTML:
<meta name="robots" content="noindex, nofollow">2. Using “No Follow” Links
The “nofollow” attribute is a powerful tool for controlling which links on your website should not be followed by search engine bots. This can be particularly useful for user-generated content, sponsored links, or other scenarios where you don’t want to pass authority to external sites. When you add the “nofollow” feature to a link, it informs search engines not to consider that link as a ranking signal.
Implementation:
To create a “nofollow” link, add the rel=”nofollow” attribute to the anchor tag:
<a href="https://example.com" rel="nofollow">Link Text</a>3. Blocking Index Pages with robots.txt
The robots.txt file is a vital tool for controlling which parts of your website search engine crawlers can access and index. If you have pages that should not be crawled, like administrative pages or private content, you can use the robots.txt file to block them. However, be cautious when using this method of website crawling, as it doesn’t guarantee that search engines won’t index these pages.
Implementation:
To block specific pages or directories, add entries like this to your robots.txt file:
User-agent: * Disallow: /private/ Disallow: /admin/4. URL Errors & Outdated URLs
Outdated or erroneous URLs can confuse both search engine crawlers and users. When a crawler encounters a broken link, it disrupts its path and can lead to missed opportunities for indexing. Regularly assess your website for broken links and update or redirect them as necessary for a successful website crawling.
Solution:
Use tools like Screaming Frog SEO Spider or online link checkers to identify broken links. Then, correct or redirect them appropriately.
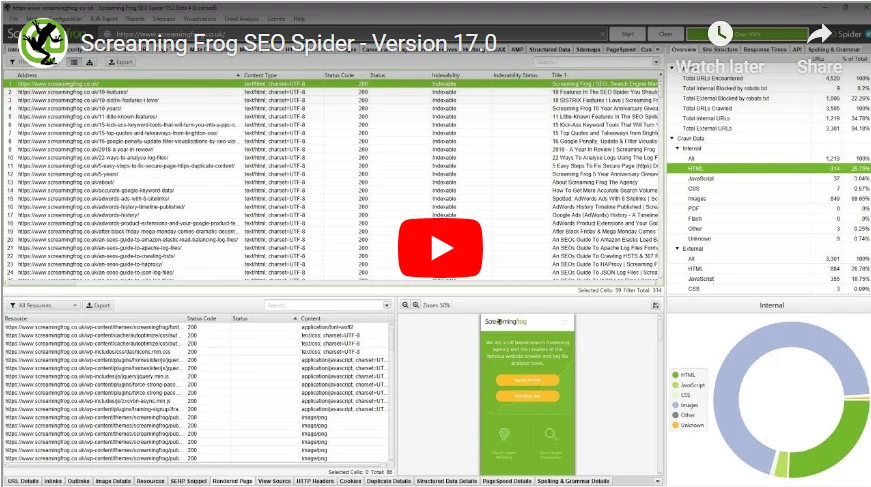
5. Implement Schema Markup
Schema markup, also known as structured data, is a potent tool for enhancing your website’s understanding by search engines. It provides a standardized way to provide structured information about your content, making it more accessible and informative in search results. By using schema markup, you can increase click-through rates and improve the user experience.
Implementation:
To implement schema markup, follow these steps:
- Identify the type of content you want to mark up, such as articles, products, events, or reviews.
- Use the schema.org website to find the appropriate schema markup for your content type.
- Add the markup to your HTML using JSON-LD or microdata format. Make sure that it accurately reflects the content on your page.
6. Get Rid of Pages with Access Denied
Pages that return “Access Denied” messages can confuse search engine crawlers and deter users. If certain pages are meant to be private or restricted, ensure they return the appropriate HTTP status codes, such as 403 Forbidden, to signal to search engines that these pages are off-limits.
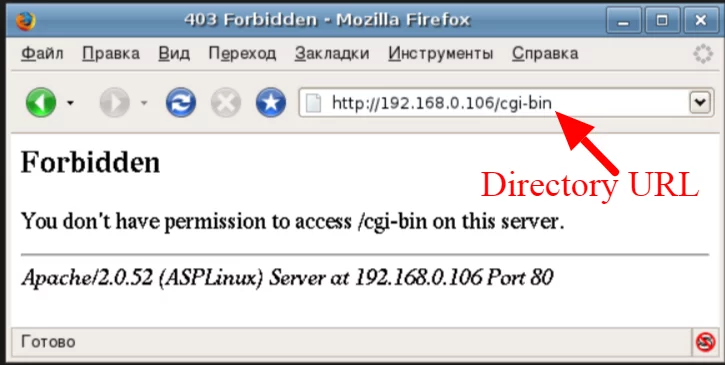
Solution:
- Review your website’s access control settings to ensure they are correctly configured for website crawling.
- Configure your server to return a 403 Forbidden status code for restricted pages.
- Create a custom error page to inform users why access is denied.
7. Resolve Server Errors & Sitemap Errors
Server errors, like the infamous 404 Not Found, can disrupt the website crawling process. Search engines rely on sitemaps to discover and index your content efficiently. Ensure your website doesn’t return server errors and that your sitemap is error-free.
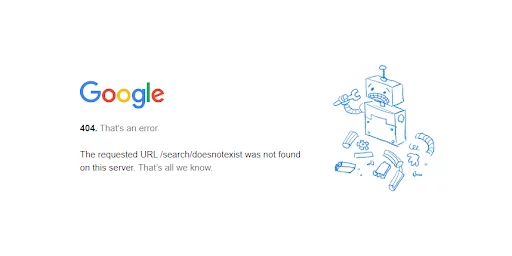
Solution:
- Monitor your website for server errors using tools like Google Search Console.
- Regularly check your sitemap for errors and correct them promptly.
- Implement 301 redirects for moved or deleted pages to avoid 404 errors.
8. Avoid Limited Server Capacity
Websites with limited server capacity may struggle to handle search engine crawlers effectively. If your server is frequently overloaded, it can lead to slow page load times and incomplete website crawling.
Solution:
- Upgrade your hosting plan to accommodate increased server capacity demands.
- Implement server-side caching and content delivery networks (CDNs) to improve server performance.
- Monitor server resource usage to ensure it can handle crawling requests.
9. Use Descriptive Headlines & Tags
Properly formatted headings (H1, H2, H3) and meta tags (title tags and meta descriptions) are fundamental for SEO and crawlability. They provide structure and context, making it easier for search engines to understand your content.
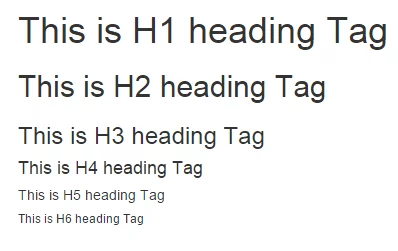
Solution:
- Make sure that each page has a unique and descriptive title tag.
- Use H1 tags for main headings and appropriate H2 and H3 tags for subheadings.
- Craft informative and enticing meta descriptions that encourage users to click on your search results and help in website crawling.
10. Correct Formatting Errors
Inconsistent or faulty HTML and CSS can hinder crawlability by confusing search engine crawlers. Validate your code regularly to ensure proper website crawling, rendering and indexing.
Solution:
- Use HTML and CSS validators to identify and correct coding errors.
- Ensure that your website follows web standards and best practices.
11. Wrong Sitemap Pages
A sitemap should accurately reflect your website’s structure and hierarchy. Incorrect or redundant entries can confuse search engine crawlers and dilute crawl resources. A well-structured website is a crucial element of good website crawling.
Solution:
- Review your XML sitemap regularly to ensure it includes only relevant and accessible pages. You can create an XML sitemap using various online tools or plugins if you’re using a content management system (CMS).
- Remove outdated or non-essential pages from the sitemap.
12. Solve Internal Link Problems
Effective internal linking is essential for both user navigation and website crawling. Ensure your links are logical, well-distributed, and provide valuable pathways for both users and search engines.
Solution:
- Conduct a thorough audit of your internal linking structure.
- Ensure that internal links use descriptive anchor text.
- Create a logical hierarchy for your website’s pages.
13. Take Care of Redirecting Problems
Improperly managed redirects can cause crawl errors and negatively impact user experience. Implement 301 redirects for permanently moved content and 302 redirects for temporary changes.

Solution:
- Use 301 redirects to permanently redirect old URLs to new ones.
- Ensure that redirected URLs are relevant and provide value to users.
14. Low Loading Speed
Slow-loading pages are a double-edged sword—they frustrate users and discourage search engine crawlers. Optimizing your site for speed is crucial for improved website crawling and user satisfaction.
Solution:
- Compress and optimize web images to reduce file size.
- Minimize the use of JavaScript and CSS to avoid render-blocking resources.
- Leverage browser caching to store frequently used resources locally.
- Opt for a content delivery network to intelligently distribute content more efficiently.
15. Dump Duplicate Pages
Duplicate content can confuse search engines and waste valuable crawl resources. It’s essential to identify and address duplicate content issues within your website.
Solution:
- Use canonical tags that points to the expected version of a web page when multiple versions are present.
- Consolidate similar or duplicate content to a single authoritative page.
- Regularly review your website to detect and rectify duplicate content.
16. Using JS and CSS
Modern websites rely on JavaScript (JS) and Cascading Style Sheets (CSS) for functionality and design. Ensure that these resources are crawlable and not blocked so search engines can understand your site’s layout and behavior.
Solution:
- Avoid using inline JavaScript and CSS whenever possible.
- Ensure that your robots.txt file doesn’t block access to essential JS and CSS files.
- Implement progressive enhancement to ensure your content remains accessible even when JS is disabled.
17. Trash Flash Content
Flash is an outdated technology that’s no longer supported by most web browsers and search engines. If your website still relies on Flash content, it’s essential to replace it with modern alternatives like HTML5 for enhancing website crawling.

Solution:
- Migrate Flash content to HTML5 or other supported technologies.
- Test your website thoroughly to test the seamless working of replaced content.
18. HTML Frames
HTML frames are outdated and can create significant problems for search engine crawlers. They disrupt the typical flow of indexing and navigation, leading to website crawling errors.
Solution:
- Replace HTML frames with a more modern layout structure using CSS.
- Implement server-side redirects to guide users and crawlers to the correct content.
19. Resolve Site Architecture Issues
A well-structured website is a strong foundation for optimal website crawling. Correcting site architecture issues ensures that search engines and users can navigate your website efficiently.
Solution:
- Arrange your website’s content into logical categories and subcategories.
- Ensure that your website’s hierarchy is reflected in your navigation menus.
- Conduct regular audits to identify and fix architectural problems.
Conclusion
Enhancing website crawling is a multifaceted endeavor that involves addressing technical, structural, and content-related aspects. By following the detailed strategies and best practices highlighted in this blog, you can create a website that’s not only optimized for search engine crawlers but also delivers a superior user experience. Remember that SEO is an ongoing process and continuous monitoring and maintenance of your website’s crawlability are essential for long-term success in the digital landscape.
FAQs
Why is website crawling important for SEO?
Crawling is vital for SEO because it directly affects how search engines understand and index your content. Without good crawlability, your web pages may not appear in search results, leading to decreased organic traffic and visibility.
How can I check if my website is crawlable by search engines?
You can make use of tools like Google Search Console or Bing Webmaster to check your website crawling. These platforms provide insights into crawl errors and indexing status.
How often do search engines crawl websites?
The frequency of website crawling can vary depending on factors like the website’s authority, update frequency, and other technical considerations. Popular and frequently updated websites tend to be crawled more often.
How can I get a surety if my website is mobile-friendly for crawlability?
To make your website mobile-friendly, use responsive design, optimize images for mobile devices, and ensure that your site’s layout and content adjust well to various screen sizes. Mobile-friendliness is crucial for website crawling and user experience.
Is there a difference between “noindex” and “nofollow” meta tags?
Yes, there is a difference. “Noindex” meta tags prevent a specific page from being indexed in search engine results, while “nofollow” attributes on links instruct search engines not to follow that link to other pages. Both are used strategically to control what search engines index.
