
In today’s Internet, web crawlers are so crucial that it’s hard to imagine navigating the web without them. Web crawlers are the backbone of search engines; they also power web archives, aid writers in determining the ownership of their work, and alert site administrators to broken links.
Web crawlers make it feasible to execute a wide variety of tasks that would be quite difficult otherwise. Marketers may find web crawlers helpful if they ever need to compile data from the web. However, it can be challenging to identify the best web crawler. This is because, unlike web scrapers, web crawlers might be harder to come by, making it more challenging to pick the right one for your needs. This is because most popular web crawlers tend to specialize.
What is a Web Crawler?
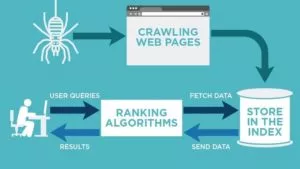
Source: https://neilpatel.com/wp-content/uploads/2018/03/crawling-web-pages.jpg
Web crawlers, also known as spiders or bots, are software programs designed to navigate the internet and collect information from websites. They are like digital explorers, tirelessly journeying through the vast and complex internet network to gather data and information.
But web crawlers are more than just tools for data extraction. They are also at the forefront of innovation in artificial intelligence and machine learning, enabling researchers and scientists to gather vast data to train and test their models.
So the next time you search for something on the internet or come across a news article, take a moment to appreciate the hard work and dedication of the web crawlers that made it all possible. They may be behind the scenes, but their impact on the internet and worldwide is genuinely remarkable.
How and Why to Have Your Site Crawled?
Your website’s ranking in SERPs may suffer if it has crawlability issues. You put a lot of effort into your company and content, but as was already mentioned, no one will know how fantastic your site is if they can’t discover it online.
Fortunately, crawling technologies like Screaming Frog and Deepcrawl can provide information on the health of your website. You can detect typical mistakes and pinpoint problems like conducting a site audit with a crawling tool.
- Broken links: When links point to a page that is no longer in existence, this not only creates a bad user experience but can also lower your SERP ranks.
- Duplicate content: When a piece of material appears many times on distinct URLs, it is challenging for Google (or other search engines) to determine which version is most pertinent to a user’s search query. Combining them with a 301 redirect is one approach for fixing this.
- Page titles: Title tags that are duplicated, missing, too long, or too short can all affect how well your page gets ranked.
Benefits of Web Crawlers:
- Data collection: These automated software programs can be designed to quickly and efficiently collect large amounts of data from the internet, making them invaluable for data collection. This data can then be analyzed to inform business decisions, research projects, or personal interests.
- Competitive intelligence: One significant advantage of web crawlers is their ability to provide competitive intelligence. By monitoring competitor websites, web crawlers can gather information about their products, pricing, and marketing strategies. This lets businesses stay informed about the competition and adjust their strategy accordingly.
- Search engine optimization (SEO): Web crawlers can also assist with search engine optimization (SEO). By gathering data about a website’s structure, content, and keywords, web crawlers can help improve its search engine ranking. This can ultimately result in increased visibility and traffic to the website.
- Content monitoring: Web crawlers can also be used for content monitoring purposes. By monitoring websites for changes in content, web crawlers can provide alerts to users when new content is added or changes are made. This is particularly useful for businesses or individuals who need to stay up-to-date with changes in their industry or interests.
- E-commerce: For e-commerce websites, web crawlers can gather pricing information for price comparison and product analysis. This can help businesses make informed decisions about pricing and product offerings.
- Research: Finally, web crawlers are helpful for research purposes. They can gather data on a wide range of topics, from tracking changes in public opinion to analyzing trends in social media. This can provide valuable insights for researchers and help inform decision-making across various fields.
Top Web Crawlers of 2023:
1. ZenRows
Best for: developers
The greatest web crawling tool is ZenRows, which allows you to quickly gather data from numerous websites without being stopped. The process is quick and simple thanks to its simplicity and ability to get over antibots and CAPTCHAs. Rotating proxies, headless browsers, and geotargeting are a few of its features. Getting started with ZenRows is free, and you’ll receive 1000 API credits to get your crawling project off the ground. After that, plans start at just $49 per month.
Pros:
- ZenRows is an easy-to-use web crawling tool that supports various programming languages such as Python, NodeJS, C#, PHP, Java, and Ruby.
- It can bypass CAPTCHAs and antibots while crawling and allows users to make multiple requests simultaneously.
- The service guarantees an uptime of up to 99.9% and provides geotargeting options with access to large proxy pools.
- It also supports HTTP and HTTPS protocols and has been thoroughly tested for extensive web scraping without being prohibited.
Cons:
- It does not offer proxy browser addons, instead relying on its smart mode to manage proxies.
2. HTTrack
Best for: copying websites
HTTrack allows you to download entire web pages onto your PC and is incredibly flexible for a free web crawling application. This free software lets people download and store all the media from a website, including photographs, so they may see it without being connected to the internet.
Pros:
- This crawler’s download speed is quick.
- Linux/Unix and Windows interfaces are multilingual.
Cons:
- Recommended for seasoned programmers.
- The anti-scraping capabilities of other web crawling technologies are necessary.
3. ParseHub
Best for: scheduled crawling
A web crawling program called ParseHub can scrape dynamic web pages. The website crawler employs machine learning to recognize the most challenging online sites and generate output files with the correct data formats. Mac, Windows, and Linux are all supported, and it is downloadable. The base plan for ParseHub is free, and the monthly cost for the premium plan is $189.
Pros:
- Data scraped by the Parsehub crawling program can be produced in various popular formats.
- Able to evaluate, analyze, and convert web material into valuable data.
- With assistance from regular expressions, scheduled crawling, IP rotation, an API, and webhooks.
- To use this site crawling program, no coding knowledge is necessary.
Cons:
- Scraping with a high volume could slow down the Parsehub process.
- This web crawling tool’s user interface makes it challenging to use.
4.Scrapy
Best for: web scraping using a free library
Python-based open-source web crawling software called Scrapy is available. Programmers can modify a web crawler and extract data from the web at scale using the library’s pre-built structure. It is a free Python crawling library that functions without a hitch on Windows, Linux, and Mac.
Pros:
- This web crawler is free.
- Both the CPU and memory usage are minimal.
- Asynchronous nature of Scrapy allows it to load several pages at once.
- It can perform extensive web scraping.
Cons:
- Antibots may pick up on Scrapy during web crawling.
- Scraping dynamic web pages is not allowed.
5. Octoparse
Best for: non-coders to scrape data
Octoparse is a no-code web crawling tool that quickly converts massive amounts of data into organized spreadsheets. A Point-and-Click Interface for data crawling, automatic IP rotation, and the capacity to scrape dynamic websites are some of its characteristics. For quick and easy applications, there is a free version of this data crawling tool. Standard packages start at $89 per month.
Pros:
- Octoparse stands out for its user-friendly interface, making it easy for beginners to use without needing coding skills.
- It can crawl dynamic web pages, similar to ZenRows, and offers automatic IP rotation for anonymous data crawling while bypassing antibot measures.
Cons:
- The lack of a Chrome extension and a feature for extracting data from PDF files.
6. Import.io
Best for: pricing analysts

Import.io is a powerful web crawling tool that offers a range of advanced features for users without coding skills. Its ability to generate custom reports and support advanced features such as geolocation and CAPTCHA resolution make it a valuable tool for businesses and researchers. However, its confusing user interface and higher price point may be a drawback for some users.
It offers daily or monthly reports that show the goods your rivals have added or removed, pricing information, including changes, and stock levels. The company offers a 14-day free trial, with monthly rates beginning at $299.
Pros:
- Easy interaction with web forms/login.
- Automated web workflows and interaction.
- It supports geolocation, CAPTCHA resolution, and JavaScript rendering.
Cons:
- The UI is confusing.
- It is more expensive than other web crawling tools.
7. Webz.io (formerly Webhose.io)
Best for: dark web monitoring
Webz.io is a premium content crawling technology that offers unparalleled capabilities for transforming online data from both the open and dark web into machine-ready structured data feeds. With Webz.io, users can enjoy a free plan that offers 1000 requests or upgrade to a premium plan after consulting with the experienced sales team.
One of the most impressive features of Webz.io is its ability to extract and organize data from the vast expanse of the internet into a format that is easily consumed by machines. This makes it an essential tool for businesses and researchers who need to quickly and efficiently process large amounts of data.
Pros:
- Easy to use.
- Smooth onboarding process.
- It can be used for real-time web scraping.
Cons:
- No transparent pricing model.
8. Dexi.io
Best for: analyzing real-time data in e-commerce

Dexi.io is a cloud-based application that specializes in crawling e-commerce websites, offering a user-friendly browser-based editor that allows users to set up real-time web crawlers to collect data. The gathered data can then be exported as CSV or JSON files or saved on cloud storage services such as Googledrive and Box.net. Users can use a free trial before upgrading to premium solutions, which start at $119 per month.
Pros:
- One of the main advantages of Dexi.io is its simple and intuitive user interface, making it accessible to users of all levels of technical expertise.
- The software also utilizes intelligent robots to automate the data collection process, while APIs can be used to build and manage the crawlers.
- Furthermore, Dexi.io is capable of extracting data from a wide range of APIs, making it versatile and suitable for a variety of applications.
Cons:
- The software requires the installation of the Dexi custom browser, which may not be convenient for some users.
- Additionally, the tool may not be suitable for complex projects that require extensive data crawling, as failure is a risk in such cases.
9. Zyte (formerly Scrapinghub)
Best for programmers who need less basic features
Zyte is a cloud-based data extraction program that leverages APIs to extract data. Its features include smart proxy management, headless browser support, residential proxies, and more. With monthly costs starting as low as $29 and a 14-day free trial, Zyte offers an affordable option for data extraction. Additionally, users can receive a 10% discount on yearly plans.
Pros:
- One of the most noteworthy features of Zyte is its user-friendly interface, which makes it easy for users to navigate the software.
- The company also provides excellent customer service, ensuring that users can easily resolve any issues they encounter.
- Zyte also offers automatic proxy rotation, support for headless browsers, and geolocation capabilities, making it a versatile tool for web crawling and data extraction.
Cons:
- The lower-tier service plans come with bandwidth restrictions, which may limit the amount of data extracted.
- Additionally, some advanced features require add-ons, which can be costly for users with limited budgets.
10. WebHarvy
Best for: SEO professionals
An easy way to quickly extract data from web pages is to use WebHarvy, a straightforward web crawler. You may extract HTML, photos, text, and URLs with the help of this web crawling program. The lowest-priced plan is $99 for a single license, and the most expensive is $499 for Unlimited Users.
Pros:
- All website types are supported by it.
- Through proxy servers or a VPN, one can access the desired websites.
- To use this site crawling program, no coding knowledge is necessary.
Cons:
- Compared to other data crawling programs, it crawls the web more slowly.
- Data loss is possible after a few days of crawling.
- When crawling, it occasionally fails.
11. ScraperAPI
Best for: testing alternative crawling APIs
Developers that create web scrapers can benefit greatly from using ScraperAPI. It is especially made to make it easier to get raw HTML from any website with only one API request. The application includes several helpful features, including support for proxy servers, browser support, and CAPTCHA handling.
It provides a 7-day trial period so programmers can evaluate the tool and learn more about its features. Users can select from several options after the trial period, with prices beginning at $49 per month.
Developers can quickly and effectively automate processes, gather useful insights, and extract information from websites using ScraperAPI. When using the program, users can scrape webpages that require JavaScript rendering and avoid being blocked by websites thanks to the application’s ability to manage proxies.
Pros:
- Usage is simple.
- A proxy pool is present.
- Antibots can be avoided by it.
- Excellent customizing options.
- It promises a 99.9% uptime rate.
Cons:
- Compared to competitors, smaller plans have a lot more restrictions.
- Using this web crawler to scrape a dynamic website is impossible.
12. UiPath
Best for: all sizes of teams
Robotic process automation (RPA) software such as UiPath is very well-liked and adaptable and is used by businesses of all sorts, from tiny to huge corporations. Its main objective is to use web crawlers to automate repetitive actions and procedures, which helps to improve productivity and streamline business operations.
The ability to create intelligent web agents without the use of programming is one of UiPath’s primary characteristics. This makes it the perfect option for both users who are less knowledgeable in coding and those who wish to have full access to the data using the.NET hacker tool. Due to their ability to configure them to meet their business requirements, customers can construct very effective web crawlers.
With the help of sophisticated automation features, customers can swiftly automate complicated company operations, which boosts productivity and lowers operating costs.
Pros:
- Easy to use.
- It has an automatic login feature so the bots can run.
Cons:
- Pricey in comparison to other crawling tools.
- Unstructured data is difficult for crawlers made with UiPath to handle.
13. OutWit Hub
Best for: small projects

OutWit Hub is an easy-to-use internet platform that enables web crawling and data extraction from online sources without technical knowledge. With the help of this effective tool, users can get any data from a range of web sources, including text, images, links, and more.
Users may quickly and efficiently extract data from webpages, blogs, and other internet sources with OutWit Hub without writing a single line of code. Due to this, even individuals without programming skills may efficiently perform web crawls and data extraction. It offers both a free and a pro version, with the pro version costing $59.90 a month and offering users more advanced features and functionalities.
Pros:
- Simple to use.
- It can perform extensive web scraping.
- Automatic creation of queries and URLs using patterns.
- Both structured and unstructured material can be crawled by it.
Cons:
- Antibots may identify it and block it.
Conclusion:
Web crawlers have become an essential tool for businesses and organizations seeking to extract valuable insights and data from the web. From e-commerce sites to news outlets, web crawlers are used to collect product information, customer feedback, and news updates, among other things. But web crawlers are more than just tools for data extraction. They are also at the forefront of innovation in fields such as artificial intelligence and machine learning, enabling researchers and scientists to gather vast data to train and test their models.
So the next time you search for something on the internet or come across a news article, take a moment to appreciate the hard work and dedication of the web crawlers that made it all possible. They may be behind the scenes, but their impact on the internet and worldwide is remarkable.
Happy crawling!
For tips on how to increase the crawlability of your website, read here.
FAQs on Web Crawlers:
What are web crawlers used for?
Web crawlers’ primary function is to gather data from websites and make it accessible to search engines so that users may conduct relevant information searches.
Can web crawlers harm websites in any way?
Web crawlers can really pose issues for websites if they are used excessively, as this can strain the servers and cause the page to run slowly. Additionally, web crawlers occasionally have the ability to illegally scrape content from websites, which can result in copyright violations and other legal problems.
How can website owners manage the interactions that web crawlers have with their websites?
Meta tags and robot.txt files are two tools website owners can employ to manage how web crawlers interact with their pages. They might employ tools to keep an eye on web crawler activity and stop undesirable crawlers.
Do all search engines use web crawlers?
Web crawlers aren’t used by all search engines, but the majority of them do, including Google, Bing, and Yahoo. But some search engines, like DuckDuckGo, use other strategies to gather data.
