
Everybody is aware of the fact that search engines serve as gateways to information. Google, being the most expansively used search engine, employs sophisticated algorithms and tools to index web pages and deliver relevant results to users. At the heart of this process lies Googlebot, a crucial component that scours the web, collecting data and updating Google’s index. Let’s delve deeper into the workings of Googlebot and its significance in the online ecosystem.
What is Googlebot?

Googlebot is Google’s web crawling bot, also known as a web spider or web crawler. It is an automated software program tasked with browsing the internet, discovering web pages, and indexing their content. Essentially, Googlebot’s primary function is to gather information from websites and feed it into Google’s massive index, which forms the basis for search results.
Google employs various crawlers for specific purposes, with each crawler identified by a distinct user agent string. Google’s bot, known for its evergreen nature, views websites akin to how users experience them on the latest Chrome browser version.
Operating across numerous machines, this bot determines the speed and scope of website crawling. However, it adjusts its crawling pace to prevent overwhelming websites with excessive traffic.
How Does Googlebot Work?
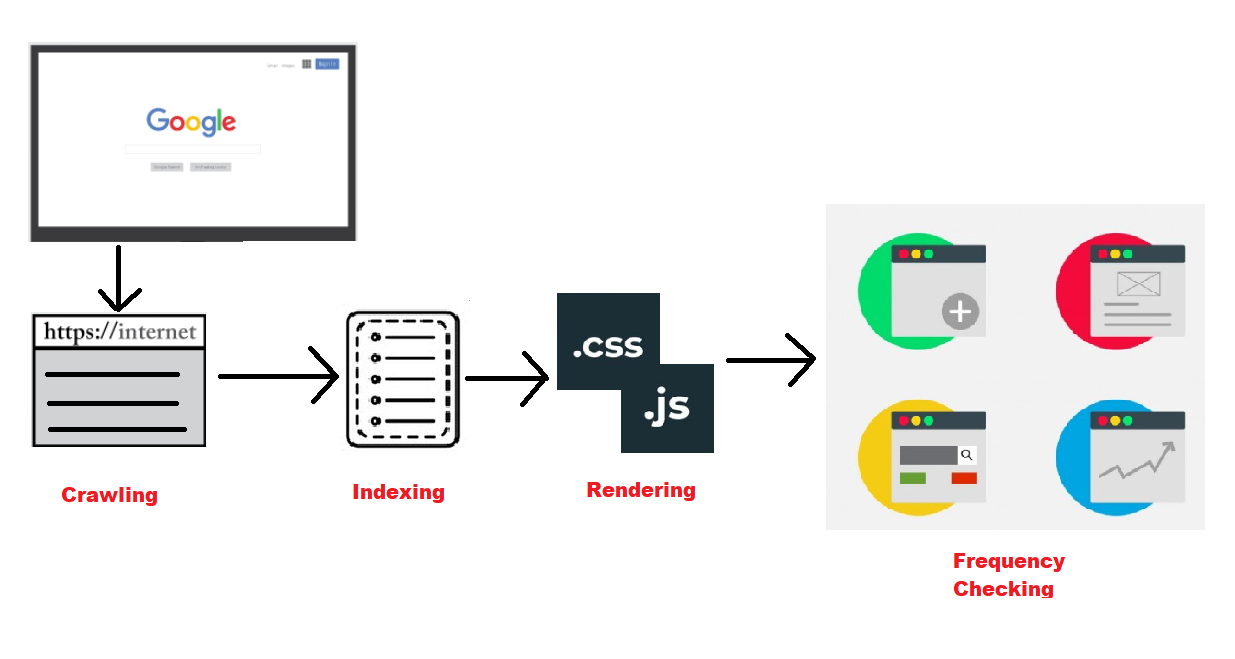
- Crawling: Googlebot starts by visiting a list of URLs, known as the crawl queue, which it gathers from previous crawls and sitemaps submitted by website owners. It accesses these pages using the website’s URL structure and follows links to other pages within the site.
- Indexing: As it navigates through web pages, it analyzes the content, including text, images, and other media. It then extracts relevant information and stores it in Google’s index, categorizing the content based on keywords, context, and other factors.
- Rendering: In recent years, Google has evolved its crawling capabilities to include rendering JavaScript and CSS elements on web pages. This ensures that the bot can accurately interpret and index dynamic content generated by modern web technologies.
- Frequency: The bot revisits web pages periodically to check for updates and changes. The frequency of crawling depends on various factors, such as the website’s authority, content freshness, and crawl budget allocated by Google.
Also Read: What is Indexing in SEO? Difference between Crawling and Indexing in Search Engine
Why Does Googlebot Matter?
- Visibility: For website owners, being indexed by Googlebot is essential for visibility in search results. Websites that are not crawled or indexed effectively may struggle to rank for relevant queries, resulting in reduced organic traffic.
- SEO Impact: Googlebot plays a pivotal role in search engine optimization (SEO). By understanding how Googlebot crawls and indexes content, website owners can optimize their sites to improve visibility and relevance in search results.
- Content Discovery: Googlebot’s continuous crawling ensures that new and updated content is promptly discovered and indexed by Google. This is especially crucial for news sites, blogs, and e-commerce platforms, where fresh content is regularly published.
- User Experience: Googlebot’s ability to render JavaScript and CSS ensures that modern websites with dynamic content are accurately represented in search results. This enhances the user experience by offering relevant and up-to-date information.
Ways to Control Googlebot
Controlling Googlebot’s behavior involves implementing various techniques to influence the crawling and indexing of your website. Here are some methods:
- Robots.txt:
Use the robots.txt file to instruct Googlebot on which pages or sections of your site to crawl or avoid. This file allows you to specify directives such as “allow” or “disallow” for different user agents, including Googlebot.
Here’s a basic example of a robots.txt file:
User-agent: *
Disallow: /private/
Disallow: /admin/
Disallow: /internal/In this example:
- User-agent: * specifies that the directives apply to all web crawlers.
- Disallow: /private/ instructs crawlers not to crawl any URLs starting with /private/.
- Disallow: /admin/ instructs crawlers not to crawl any URLs starting with /admin/.
- Disallow: /internal/ instructs crawlers not to crawl any URLs starting with /internal/.
You can also use the Allow directive to specify exceptions to Disallow directives.
To create and implement a robots.txt file on your website, follow these steps:
- Create a text file named robots.txt.
- Add the appropriate directives to the file using a text editor.
- Place the robots.txt file in the root directory of your website (e.g., https://www.example.com/robots.txt).
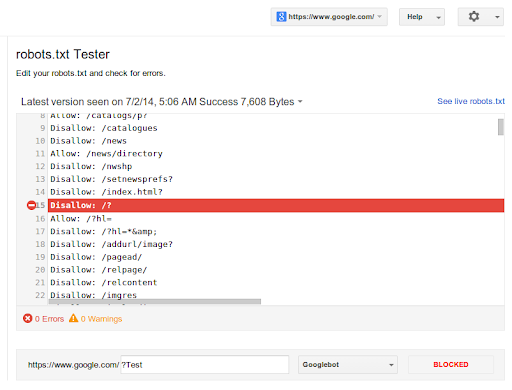
- Test the robots.txt file using Google’s robots.txt Tester tool in Google Search Console or other similar tools.
- Upload the robots.txt file to your web server.
- Meta Robots Tags:
Incorporate meta robots tags within your HTML code to provide specific instructions to search engine crawlers. These tags can indicate whether a page should be indexed, followed, or excluded from search results. Here’s an overview of the most commonly used meta robots directives:
- noindex: This directive instructs search engines not to index the content of the page. It prevents the page from appearing in search engine results pages (SERPs). Example: <meta name=”robots” content=”noindex”>
- nofollow: This directive instructs search engines not to follow the links on the page. It prevents search engines from passing link equity (PageRank) to the linked pages. Example: <meta name=”robots” content=”nofollow”>
- noarchive: This directive instructs search engines not to store a cached copy of the page. It prevents search engines from displaying a cached version of the page in search results. Example: <meta name=”robots” content=”noarchive”>
- nosnippet: This directive instructs search engines not to display a snippet of the page’s content in search results. It prevents search engines from displaying a preview of the page’s content. Example: <meta name=”robots” content=”nosnippet”>
- noimageindex: This directive instructs search engines not to index images on the page. It prevents images from appearing in image search results. Example: <meta name=”robots” content=”noimageindex”>
- max-snippet:-1, max-image-preview:large, max-video-preview:-1: These directives allow you to control the maximum length of the snippet, image preview, and video preview, respectively. Example: <meta name=”robots” content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1″>
You can use these meta robots directives individually or combine them as needed within a single <meta> tag. For example:
<meta name="robots" content="noindex, nofollow">- XML Sitemaps:
Craft and submit XML sitemaps to Google Search Console to help Googlebot discover and crawl all the pages on your website efficiently. Sitemaps provide valuable information about the structure and priority of your site’s content. Make use of tools like XML Sitemap Generator for Google for creating sitemaps.
- Crawl Budget Optimization:
Manage your website’s crawl budget effectively by prioritizing important pages, minimizing duplicate content, and fixing crawl errors. This ensures that Googlebot spends its allocated resources crawling and indexing your most valuable content.
- Page Speed Optimization:
Improve your website’s loading speed to facilitate faster crawling and indexing by Googlebot. Optimize images, minimize server response times, and leverage caching techniques to enhance overall performance.
- Mobile-Friendly Website Design:
Verify the responsive and mobile-friendliness of your website, as Googlebot primarily crawls and indexes mobile versions of web pages. A mobile-friendly design not only enriches user experience but also enhances visibility in mobile search results.
- Canonicalization: Implement canonical tags to specify the preferred version of duplicate or identical content on your site. This helps Googlebot understand which URL to prioritize when indexing content, preventing duplicate content issues.
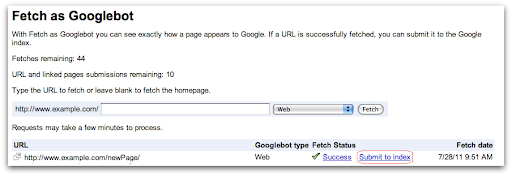
- Fetch as Google:
Use the Fetch as Google tool in Google Search Console to request indexing of specific pages or resources on your website. This allows you to control when Googlebot crawls and updates content that may have recently changed.
By implementing these tactics, you can effectively control Googlebot’s crawling and indexing behavior to ensure optimal performance of your website in search engine results.
Is it Truly Googlebot?
Several SEO tools and even some malicious bots often masquerade as Googlebot, potentially gaining access to websites attempting to block them.
Previously, verifying whether a bot was Googlebot required a DNS lookup. However, Google has simplified this process by providing a list of public IPs for verification purposes. Website owners can cross-reference these IPs with their server logs to confirm Googlebot’s authenticity.
Additionally, Google Search Console offers a “Crawl stats” report accessible under Settings > Crawl Stats. This report furnishes comprehensive data on Google’s crawling activities, detailing which Googlebot accessed specific files and when the access occurred.
Conclusion
Googlebot served as the backbone of Google’s search engine, tirelessly traversing the web to index and organize vast amounts of information. Understanding how Googlebot works and its impact on search visibility is paramount for website owners and digital marketers looking to succeed in the competitive online landscape. By optimizing websites for Googlebot and adhering to best practices in SEO, businesses can enhance their online presence and reach a broader audience effectively.
FAQs
Does Googlebot crawl mobile versions of websites?
Yes, Googlebot primarily crawls and indexes mobile versions of web pages. It’s mandatory to ensure your website is mobile-friendly to improve visibility in mobile search results.
What should I do if Googlebot is not crawling my website properly?
If you encounter issues with Googlebot’s crawling or indexing of your website, it’s essential to troubleshoot and address any underlying issues promptly. This may involve fixing crawl errors, improving site performance, ensuring mobile-friendliness, and optimizing content for better visibility in search results.
How often does Googlebot crawl my website?
The frequency of Googlebot’s crawling depends on various factors, including the website’s authority, content freshness, and crawl budget allocated by Google. While some pages may be crawled frequently, others may be revisited less frequently based on their importance and update frequency.
