
Crawl errors arise when search engine crawlers encounter difficulties navigating through your webpages as usual. When this happens, search engines such as Google are unable to thoroughly explore and comprehend the content or structure of your website.
This poses a problem because crawl errors hinder the discovery of your pages. Consequently, these pages may not be indexed, appear in search results, or attract organic (unpaid) traffic to your site.
Google classifies crawl errors into two main categories: site errors and URL errors.
Types of Crawl Errors
Site Errors
Site errors encompass crawl errors that can affect your entire website. The most common types include server, DNS, and robots.txt errors.
1. Server Errors
Server errors, indicated by a 5xx HTTP status code, occur when the server prevents a page from loading properly. They disrupt user access to the website and can harm user experience. Additionally, they may prevent search engine bots from properly crawling and indexing the site, potentially leading to decreased visibility in search results.
The following are typical server errors:
- Internal server error (500): Occurs when the server cannot fulfill the request, sometimes due to unspecified issues.
- Bad gateway error (502): Arises when one server acting as a gateway receives an invalid response from another server.
- Service not available error (503): Indicates that the server is currently unavailable, often during maintenance or updates.
- Gateway timeout error (504): Occurs when one server acting as a gateway does not receive a response from another server within a specified time frame, often due to excessive website traffic.
Frequent encounters with 5xx errors by search engines can impede a website’s crawling rate. Consequently, search engines like Google may struggle to discover and index all of your website’s content.
2. DNS Errors
When search engines are unable to establish a connection with your domain, it results in a domain name system (DNS) error.
Every website and device on the internet possesses at least one unique Internet Protocol (IP) address, serving as their identifier on the web.
The DNS simplifies communication between people and computers by correlating domain names with their corresponding IP addresses.
Without the DNS, accessing websites would entail manually inputting their IP addresses instead of their URLs.
For instance, instead of typing “www.nestify.io” in your URL bar, you would need to utilize its IP address: “34.120.45.191.”
While DNS errors are less prevalent compared to server errors, here are some you might encounter:
- DNS Timeout: This occurs when your DNS server fails to respond to the search engine’s request promptly.
- DNS Lookup Failure: This happens when the search engine cannot access your website because your DNS server struggles to locate your domain name.
3. Robots.txt Errors
When search engines are unable to retrieve your robots.txt file, it results in robots.txt errors.
The robots.txt file instructs search engines on which pages are allowed to crawl and which ones are not.
Here’s a basic example of a robots.txt file:
User-agent: *
Disallow: /private/
Disallow: /admin/
Disallow: /internal/In this example:
- User-agent: * specifies that the directives apply to all web crawlers.
- Disallow: /private/ instructs crawlers not to crawl any URLs starting with /private/.
- Disallow: /admin/ instructs crawlers not to crawl any URLs starting with /admin/.
- Disallow: /internal/ instructs crawlers not to crawl any URLs starting with /internal/.
URL Errors
1. 404 Errors (Page Not Found)
When a search engine or user attempts to retrieve a page on your website that no longer exists, a 404 error is returned. This status code points out that the requested resource is not found on the server. It can cause due to multiple reasons such as the page being deleted, moved, or the URL being mistyped.
404 errors can frustrate users and harm user experience. They also signal to search engines that the page is not available, potentially leading to a drop in rankings for that page or the site as a whole.
Today, the majority of companies utilize custom 404 pages, which serve to enhance the user experience while maintaining consistency with the website’s design and branding.
2. Soft 404 Errors
Soft 404 errors appear when a page that does not exist returns a “200 OK” status code instead of the appropriate 404 status code. This can happen when a website’s server incorrectly handles requests for non-existent pages, either by displaying a generic error page or redirecting users to a different page.
Soft 404 errors can confuse search engines, as they may interpret the page as valid content rather than recognizing it as an error. This can lead to improper indexing and potentially lower rankings for the affected pages.
What Leads to Soft 404 Errors?
- Issues with JavaScript Files: When the JavaScript resource is blocked or unable to load properly.
- Thin Content: Pages with insufficient content that fail to provide significant value to the user, such as empty internal search result pages.
- Low-Quality or Duplicate Content: Pages that lack usefulness to users or are duplicates of other pages. Examples include placeholder pages containing “Lorem Ipsum” content or duplicate content lacking canonical URLs, which inform search engines of the primary page.
- Other Factors: Missing files on the server or a disrupted connection to the database.
3. 403 Forbidden Errors
The 403 forbidden error appears when the server denies a crawler’s request, indicating that while the server comprehended the request, the crawler is unable to access the URL.
Issues with server permissions are the primary causes of the 403 error. Server permissions dictate the rights of users and admins regarding a folder or file, categorized into read, write, and execute permissions. For instance, if you lack read permission, accessing a URL becomes impossible.
Another common cause of 403 errors is a faulty .htaccess file. The .htaccess file, utilized on Apache servers, serves as a configuration file for settings and redirects. However, any error within the .htaccess file can lead to issues like a 403 error.
4. Redirect Errors

Redirect errors appear when there are problems with URL redirections on a website. This could include broken or incorrect redirects, resulting in a poor user experience and potential SEO implications.
Redirect errors can confuse users and search engine bots, as they may encounter unexpected redirects or dead-end chains of redirects. This can lead to indexing issues and decreased search engine rankings for affected pages.
For example, a website implements a redirect from one URL to another, but the redirect is misconfigured, resulting in a loop or redirecting users to an irrelevant page.
Resolving Crawl Errors
Resolving crawl errors is important for ensuring that search engines can productively crawl and index your website’s content. By addressing these errors promptly, you can improve the visibility of your website in SERP and enhance the user experience. Below, we’ll delve into the steps involved in resolving crawl errors, along with the necessary tools required for the process.
1. Identify Crawl Errors: The first step in resolving crawl errors is to identify the crawl errors affecting your website. You can use various tools to accomplish this, including:
- Google Search Console: Google Search Console provides detailed reports on crawl errors encountered by Google’s crawlers. It offers insights into both site-wide errors and specific URL errors.
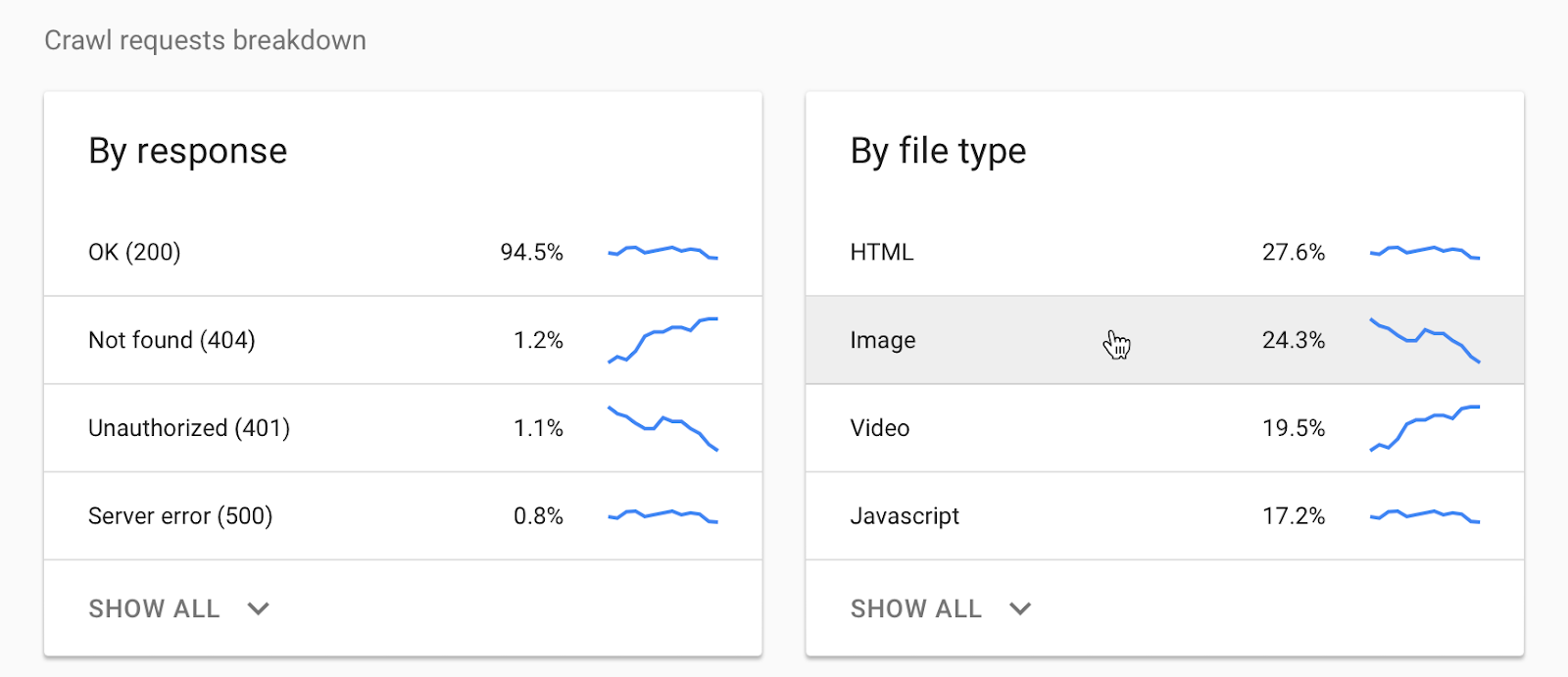
- Bing Webmaster Tools: Similar to Google Search Console, Bing Webmaster Tools offers reports on crawl errors encountered by Bing’s crawlers.
- Third-party SEO Tools: Many third-party SEO tools, such as SEMrush, Ahrefs, and Moz, offer comprehensive site auditing features that can identify crawl errors and provide actionable insights.
2. Understand the Nature of Crawl Errors: Once you’ve identified the crawl errors, it’s essential to understand their nature and underlying causes. Common types of crawl errors include 404 errors, soft 404 errors, server errors (5xx errors), redirect errors, DNS errors, and robots.txt errors.
3. Resolve Site-wide Issues: Begin by addressing any site-wide crawl errors that impact your entire website. These may include server-related issues, DNS configuration errors, or problems with your robots.txt file. You can test this file using Google’s robots.txt Tester Tool.
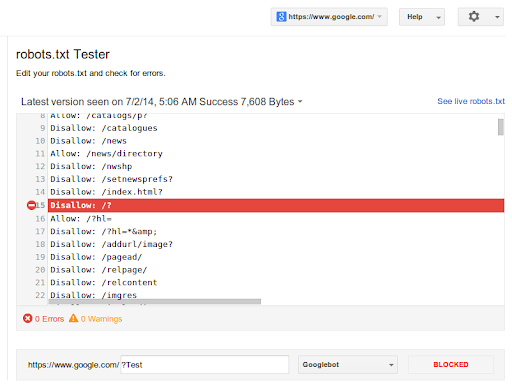
Ensure that your website’s server is properly configured, your DNS settings are accurate, and your robots.txt file allows search engines to crawl essential pages while blocking irrelevant or sensitive content.
4. Fix URL-specific Errors: Next, focus on resolving crawl errors specific to individual URLs on your website. This may involve fixing broken links, updating incorrect redirects, or optimizing page content to prevent soft 404 errors. Use the following tools and techniques to address URL-specific crawl errors:
- Broken Link Checkers: Tools like Screaming Frog, Xenu Link Sleuth, or Online Broken Link Checker can help identify broken links on your website.
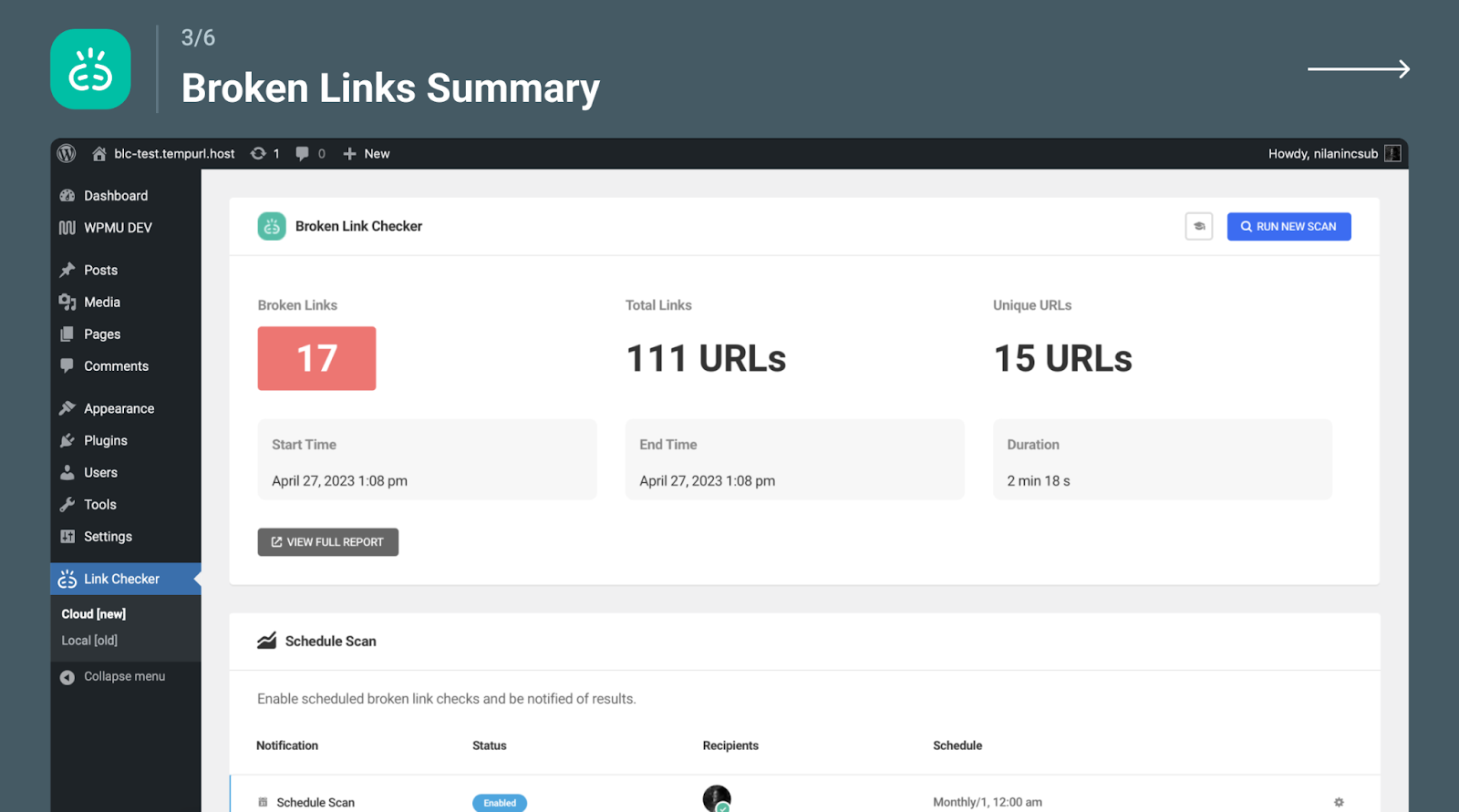
- Redirect Checkers: Use tools like Redirect Checker or Redirect Path to identify and fix incorrect or broken redirects.
- Content Optimization Tools: Tools like Copyscape or Siteliner can help identify duplicate content issues that may lead to soft 404 errors.
5. Monitor and Maintain: Once you’ve resolved crawl errors, it’s crucial to monitor your website routinely to ensure that new errors don’t emerge. Set up ongoing monitoring using tools like Google Search Console, Bing Webmaster Tools, or third-party SEO platforms. Additionally, regularly audit your website’s content and technical infrastructure to identify and address any potential crawl issues proactively.
By following these steps and leveraging the necessary tools, you can effectively resolve crawl errors and equip your website for better search engine visibility and user experience.
Conclusion
Crawl errors can significantly impact your website’s search engine rankings and user experience. By understanding the types, causes, and solutions for crawl errors outlined in this guide, you can effectively optimize your website and ensure smooth crawling and indexing by search engines. Regular monitoring and proactive maintenance are key to keeping crawl errors at bay and maintaining a healthy website presence online.
FAQs
How do crawl errors impact SEO?
Crawl errors negatively impact a website’s SEO by preventing search engines from properly indexing its pages. This can lower your search engine rankings, reduced organic traffic, and ultimately, diminished online visibility and potential revenue.
What are some best practices for preventing crawl errors?
To prevent crawl errors, website owners should:
- Regularly monitor crawl error reports provided by search engine tools.
- Conduct regular website audits to identify and fix potential issues proactively.
- Ensure consistent URL structures and avoid using dynamic parameters whenever possible.
- Implement proper redirects for outdated or removed pages to maintain SEO value.
- Keep robots.txt files up-to-date and accurately configured to guide search engine crawlers.
How often should crawl errors be monitored and fixed?
Crawl errors should be monitored and fixed regularly to maintain optimal website performance and SEO. It’s recommended to check crawl error reports at least once a month and take action against any issues promptly to prevent negative impacts on search engine rankings and organic traffic.
