
Managing an ecommerce site involves handling vast amounts of data and numerous web pages, all of which need to be efficiently indexed by search engines. However, excessive ecommerce requests can quickly waste your crawl budget. When search engines allocate a limited crawl budget to your site, every unnecessary or redundant request can consume valuable resources that could be better spent on indexing essential pages. Understanding and optimizing your crawl budget is crucial for maintaining up-to-date content and improving your site’s visibility in search results.
Why Ecommerce Sites Should Care About Crawl Budget Optimization:
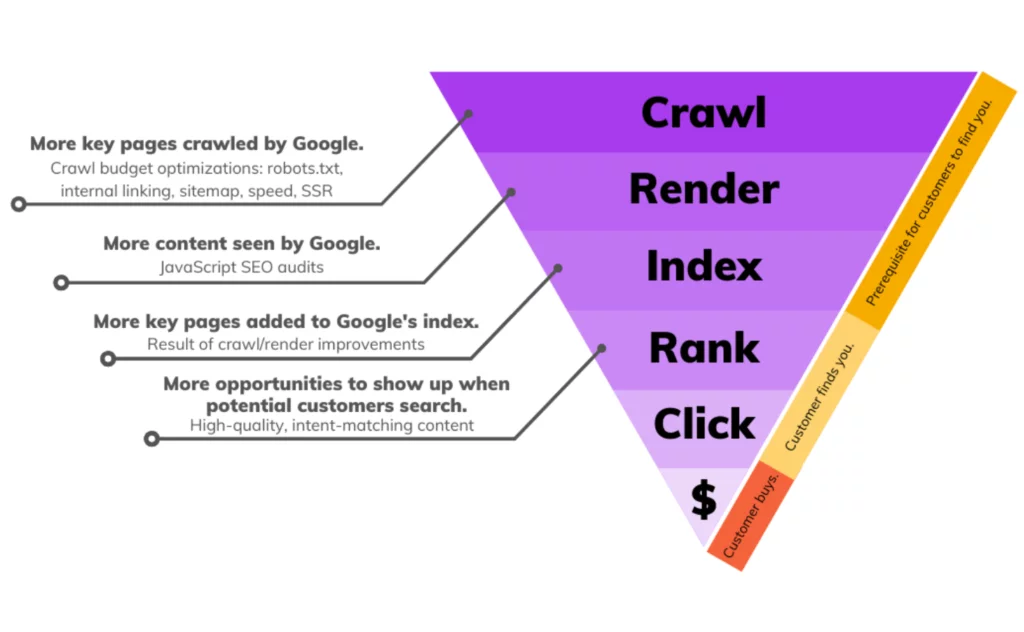
Ecommerce websites are complex, dynamic entities. With hundreds of thousands of product pages that are frequently updated for availability, prices, and reviews, the structure of an ecommerce site is constantly shifting. This dynamic nature generates a massive number of URLs and a surge in crawling JSON requests.
Here’s the issue: every time a search engine crawls and reindexes your site, it uses up your crawl budget. With hundreds of product listings requiring attention, your crawl budget can quickly be exhausted. This leads to slow indexation, resulting in outdated content being displayed in search results, and potentially missing out on indexing some pages altogether.
Moreover, the high volume of product pages is not the only factor that can deplete your ecommerce crawl budget. Various other “ecommerce requests” are often overlooked but can significantly impact your crawl rate performance. Managing these effectively is crucial to ensure that your most important pages are being crawled and indexed regularly, maintaining the freshness and accuracy of your site’s content.
Learn about core web vitals here,
What are eCommerce Requests?
In the context of crawl budget, eCommerce requests refer to the several types of HTTP requests generated when search engine crawlers (such as Googlebot) interact with an eCommerce website.
Search engine crawlers do not modify website data; they simply read and analyze it. The most common eCommerce requests that search crawlers make are GET requests designed to retrieve information from a server.
While these eCommerce requests are essential for your website’s functionality and user experience, they can significantly deplete your crawl budget if not managed proactively. Properly handling these requests ensures that your most important pages get the attention they need from search engines, helping to maintain and improve your site’s visibility and performance in search results.
Issues Related to Ecommerce Requests and Crawl Budgets:
A. Duplicate Content
Problem
One of the biggest crawl budget killers for eCommerce sites is duplicate content. Consider product variations based on color, size, or other minor details. Each variation often gets its unique URL, resulting in multiple pages with nearly identical content.
When search engines encounter multiple URLs leading to essentially the same content, they face a dilemma: Which version should they index as the main page? How should they allocate their finite crawling resources? Consequently, Googlebot may waste your crawl budget indexing all variations, which could be more efficient.
This problem frequently occurs on retail sites for several reasons:
- Product Variations: A single product can have numerous SKUs (Stock Keeping Units) with unique URLs due to differences in size, color, material, etc. While these variations are valuable for customers, they create technically distinct pages with the same core content for search engine crawlers.
- Session IDs and Tracking Parameters: Dynamic URLs, such as those with session IDs, affiliate codes, and tracking parameters, often get appended to product and category URLs. This results in many seemingly identical URLs from a search engine’s perspective.
- Faceted Navigation: Modern eCommerce platforms offer robust filtering and faceting options to refine product searches. However, each filter combination applied to a category page generates a new URL, potentially leading to duplicate content.
From a search engine’s perspective, these factors can generate hundreds or even thousands of identical URLs. This dilutes the link equity and authority of your most valuable product and category pages, reduces page speed, and forces crawlers to save time sifting through redundant content.
How Can Content Audit Help You To Understand Your Content’s Potential?
Solution
Deleting or merging duplicate content is crucial to reclaiming your crawl budget. Here are the steps to guide Google on crawling URLs more efficiently:
Step 1: Identify Duplicate Content
Use website crawling tools like Screaming Frog or SEMrush Site Audit to identify duplicate pages. The free version of Screaming Frog might be sufficient for smaller websites with limited budgets. Still, if you need a more comprehensive SEO audit with advanced reporting and prioritization, SEMrush Site Audit could be a better choice.
Step 2: Consolidate Duplicate Pages
Instead of having separate URLs for product variations (like color and size), consider consolidating them onto a single page with clear filtering options. This reduces the number of URLs competing for the crawl budget and ensures unique content is prioritized.
Step 3: Leverage “Noindex”
Use the robots.txt file to block out-of-stock product pages and unwanted pages from being crawled. This helps Googlebot save on its crawl budget for irrelevant content. Visit our guide for detailed instructions on how to apply the robots.txt directive to your website.
Page Load Techniques For Improving Website Speed to 2X
B. Infinite Scrolling
Problem
Infinite scrolling enhances user experience by continuously loading more products as the user scrolls down a page. While this is great for user engagement, it presents a challenge for search engine crawlers.
Search engines primarily rely on the initial content loaded on a webpage for indexing. They send a GET request for this content, which includes product information, descriptions, and category listings.
With infinite scrolling, additional product information and listings are loaded dynamically as the user scrolls. Since Googlebot prioritizes what it sees on the first page load, essential products buried deeper within the infinite scroll are entirely missed.
This results in missing content, as products loaded further down the infinite scroll become invisible to search engines. Consequently, the overall picture of your offerings presented to search engines needs to be completed, leading to inaccurate search results and hindering your organic reach.
Solution
There are several ways to address this issue:
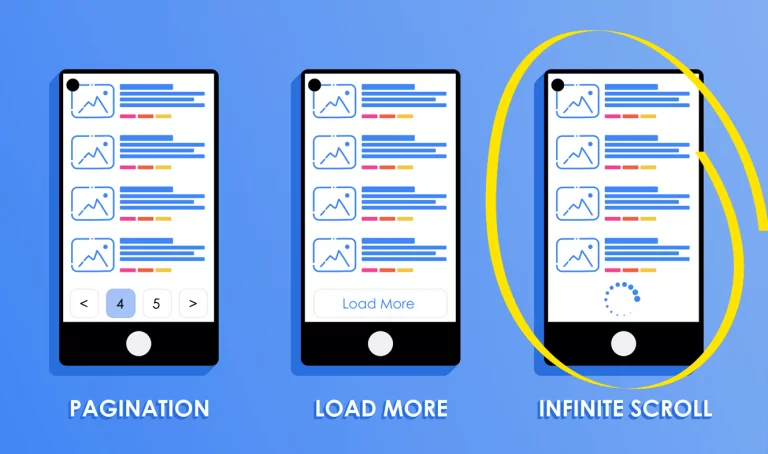
- Implement “Load More” Functionality
Instead of infinite scrolling, a “Load More” button dynamically loads additional products without generating new URLs. This technique makes it easier for search engines to crawl and index all products.
- Use Canonical Tags
Ensure the main category page URL is canonical for all paginated URLs. This consolidates link equity and helps manage your crawl budget more efficiently.
- Pagination
While less user-friendly than infinite scrolling, pagination allows Googlebot to see all available product listings on separate pages, ensuring complete indexing.
To save the crawl budget, consider setting a sensible limit on the number of paginated URLs generated, such as only crawling the first 10-20 pages. Use robots.txt or meta robots tags to prevent search engines from crawling deeper paginated URLs.
Ecommerce Product Pages Not Ranking? Here are 10 Ways to Fix These SEO Issues
C. Unoptimized Ecommerce JavaScript Content
Problem
JavaScript-generated content is a significant factor that can deplete the crawl budgets of ecommerce sites.
Modern ecommerce platforms heavily rely on JavaScript frameworks like React, Angular, and Vue to deliver dynamic content, interactive features, and personalization. While JavaScript (JS) enhances user experience (UX), it poses challenges for search engine crawlers as they need help parsing and fully understanding rendered JS content.
This complexity means search engine crawlers require a larger crawl budget to index JS-based content effectively. Consequently, this leaves little of your crawl budget for other pages. Additionally, pages with complex JavaScript can take longer to load fully, a known negative ranking factor for search engines.
Solution
Several strategies can address the issue of JavaScript consuming your crawl budget, such as minifying JavaScript or using server-side rendering (SSR). However, prerendering JavaScript is the most effective method for optimizing JavaScript crawl budgets in ecommerce sites.
Prerendering involves preparing a static version of your content. Essentially, Nestify enders your JS content ahead of time and serves this static version to crawlers. This approach offers several technical SEO benefits for your ecommerce site:
- Save Your Valuable Crawl Budget
Since Nestify processes your JS content, Googlebot will use less crawl budget to index your pages, conserving your crawl limit.
- Ensure No Content is Missed
All your SEO elements and valuable product information will be fully indexed, even if the pages rely heavily on complex JavaScript code.
- Faster Response Time
Nestify addresses JavaScript SEO issues for ecommerce sites and improves page load speeds by reducing server response times (SRT) to less than 50 milliseconds.
Conclusion:
Improving your ecommerce site’s speed is essential for providing a superior user experience, retaining customers, and boosting conversion rates. A fast-loading website not only improves the user experience but also positively impacts the search engine rankings, which can lead to increased organic traffic. Consistent monitoring and optimization are key to maintaining these benefits. By incorporating regular speed testing into your broader optimization strategy and routinely reviewing all new and modified pages, you ensure that your site remains efficient and responsive, meeting the evolving needs of your customers.
How do redirects impact site speed, and how can I manage them effectively?
Redirects can significantly slow down your site by adding extra HTTP requests and increasing server response times. Minimize redirects by regularly auditing your site and removing unnecessary ones. Use tools like Screaming Frog to identify and eliminate redirect chains.
What is the role of compression in improving site speed?
Compression reduces the size of your web files, making them faster to transfer and load. Implementing gzip compression can cut file sizes by up to 70%, leading to quicker page load times.
