
Large language models (LLMs) are gaining widespread attention as one of the most talked-about technological advances in the Internet era.
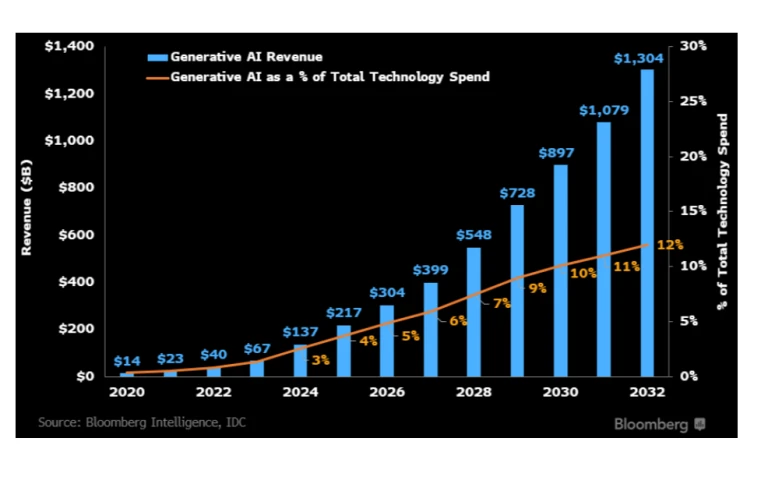
Researchers predict that generative AI, including solutions like ChatGPT, Google Bard, and Bing Chat, will evolve into a $1.3 trillion market by 2032, driven by increasing user exploration and adoption.
Despite the excitement, the specific applications of LLMs in the business world are still emerging due to the technology being in its early stages.
Initially, LLMs show potential in various scenarios where organizations need to analyze, process, summarize, rewrite, edit, transcribe, or extract insights from datasets or text inputs. As adoption grows, some practical applications of language models are starting to show promise.
So, in this article, you’ll learn more about LLM large language models and how they work, LLM applications, and their tools to use in your project.
So, let’s get right into it.
What is LLM – Large Language Model?
A large language model (LLM) is an artificial intelligence (AI) program that relies on deep learning techniques and vast data sets to comprehend, summarize, synthesize, and anticipate new text. The phrase generative AI is also closely related to LLMs, which are a sort of generative AI designed exclusively to produce text-based material.
Over millennia, people developed spoken languages to communicate. Language is important to all kinds of human and technology communication; it supplies the words, semantics, and grammar required to express ideas and concepts. A language model serves a similar role in the field of artificial intelligence, serving as a foundation for communication and the generation of new ideas.
Before generating new content based on the learned data, language models undergo training on the collection of data using several ways to infer associations. In natural language processing (NLP) applications, language models are frequently used to create results when a user types a query in natural language.
The AI language model idea has evolved into an LLM, which significantly increases the amount of data available for inference and training. As a result, the AI model’s capabilities are greatly increased. An LLM usually includes at least one billion or more parameters, while the exact size of the training data set needs to be widely agreed upon. The variables in the model that were used to train it and allow for the inference of additional material are referred to as parameters in machine learning.
Best LLM Applications
1. Using Language Models for Translation
Translating printed documents is one of the most straightforward practical uses for LLMs. When a user enters text into a chatbot and requests a translation into a different language, the chatbot will initiate the translation process automatically.
According to some research, LLMs like GPT-4 outperform commercial translation services like Google Translate. However, experts also point out that GPT-4 performs best when translating European languages; it is less accurate when translating “distant” or “low-resource” languages.
2. Content Creation – Text, Images and Videos
The generation of content is another increasingly popular use case for language models. With LLMS, users may create a variety of written material, such as articles, blogs, summaries, scripts, polls, quizzes, and social media postings. The information in the original prompt determines how well these outputs turn out.
LLMs can be used to aid with ideation if they aren’t utilized to create material directly. Hubspot reports that 33% of marketers that employ AI do so to come up with concepts or sources of inspiration for marketing material.

The primary benefit here is that artificial intelligence may expedite the creation of content.
It is noteworthy that users may also create graphics in response to textual prompts using programs such as DALL-E, MidJourney, and Stable Diffusion.
3. Search
As an alternative search tool, generative AI will have initially been tried by a large number of people. Customers may ask a chatbot natural language inquiries, and it can respond instantly with information and analysis on almost any subject.
Although you may get a lot of information by using search tools like Bard or ChatGPT, you should be mindful that not all of the material is reliable.
Language models frequently create facts and numbers out of thin air and are prone to hallucinations. Therefore, in order to prevent being duped by false information, it is advisable for consumers to confirm any accurate information provided by LLMs.
4. Customer service and virtual assistants
As virtual assistants, generative AI seems to have promise in the field of customer service.
According to a McKinsey study, the use of generative AI shortened issue-handling times by 9% and improved issue resolution by 14% per hour at a firm with 5,000 customer care representatives.
Customers may rapidly register concerns, seek refunds, and ask inquiries about services and products via AI virtual assistants. It saves staff time by automating repetitive support procedures, and it relieves end customers of having to wait for a human support representative.
5. Cyberattack Detection and Prevention
Detecting cyberattacks is an additional intriguing cybersecurity use case for language models. This is due to the fact that LLMs can scan massive data sets gathered from several sources inside a corporate network, identify patterns that point to a hostile cyberattack, and then raise an alarm.
Numerous cybersecurity providers have so far started experimenting with threat detection technology. SentinelOne, for instance, unveiled an LLM-driven solution at the beginning of the year that can automatically detect threats and launch automated reactions to malicious activities.
Another strategy, shown by Microsoft Security Copilot, enables users to quickly produce reports on possible security events and scan their surroundings for known vulnerabilities and exploits, therefore preparing human defenders for action.
Wrapping up
Large Language Models (LLMs) represent a groundbreaking advancement in artificial intelligence, leveraging deep learning techniques and massive datasets to understand, generate, and predict textual content. These models, a subset of generative AI, have evolved from the early days of AI language models like Eliza, expanding their capabilities through extensive training and increased parameter sizes.
LLMs find applications across various domains, serving as powerful tools for natural language processing (NLP) tasks. Their ability to analyze, summarize, and generate text opens up possibilities for enhancing communication and information processing in both human and technological interactions.
As the field continues to progress, LLMs are poised to revolutionize how we approach language-related tasks, offering solutions to challenges such as information extraction, content creation, and communication. The future harbors exciting prospects for the integration of LLMs in diverse industries, shaping the way we interact with and utilize textual information.
FAQs on Large Language Model
How do LLMs differ from traditional language models?
LLMs represent an evolution of traditional language models by significantly expanding the scale of data used for training and inference. They typically have at least one billion or more parameters, enhancing their capabilities to comprehend and generate content.
What are the applications of LLMs?
LLMs find applications in various scenarios, including natural language processing tasks such as analyzing, summarizing, rewriting, editing, transcribing, and extracting insights from datasets or input text. They are powerful tools for improving communication and information processing.
What sets LLMs apart in the AI landscape?
LLMs stand out for their ability to process and generate textual content at a massive scale, providing solutions to challenges related to language comprehension and communication. Their extensive training datasets and parameters contribute to their effectiveness.
How large are the training datasets for LLMs?
While there is no universally accepted figure, LLMs typically have training datasets with at least one billion or more parameters. These parameters are crucial variables derived from the training data, contributing to the model’s ability to infer new content.
